Shujian Zhang
Google Deepmind; zhangshujian2023@gmail.com

I am a Research Scientist at Google DeepMind, working on Gemini. My research focuses on natural language processing and machine learning, with a particular emphasis on the post-training of large language models. I am especially interested in instruction tuning, preference modeling, and reinforcement learning from human feedback.
I completed my Ph.D. at the University of Texas at Austin, advised by Prof. Mingyuan Zhou. Prior to that, I obtained my Bachelor’s degree from University of Rochester. During my PhD, I also did some fun internships at Salesforce Research (Summer 2023) and Microsoft Azure AI (Summer 2021 - Winter 2022).
news
| Jul 07, 2025 | Our Gemini 2.5 Technical Report is released ArXiv. |
|---|---|
| May 15, 2025 | I will serve as an Area Chair for EMNLP 2025. |
| May 15, 2025 | Our T-REG: Preference Optimization with Token-Level Reward Regularization is accepted by ACL 2025. |
| Jan 22, 2025 | Our Instructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy is accepted by ICLR 2025. |
| Sep 18, 2024 | Our WPO: Enhancing RLHF with Weighted Preference Optimization is accepted by EMNLP 2024. |
selected publications
-
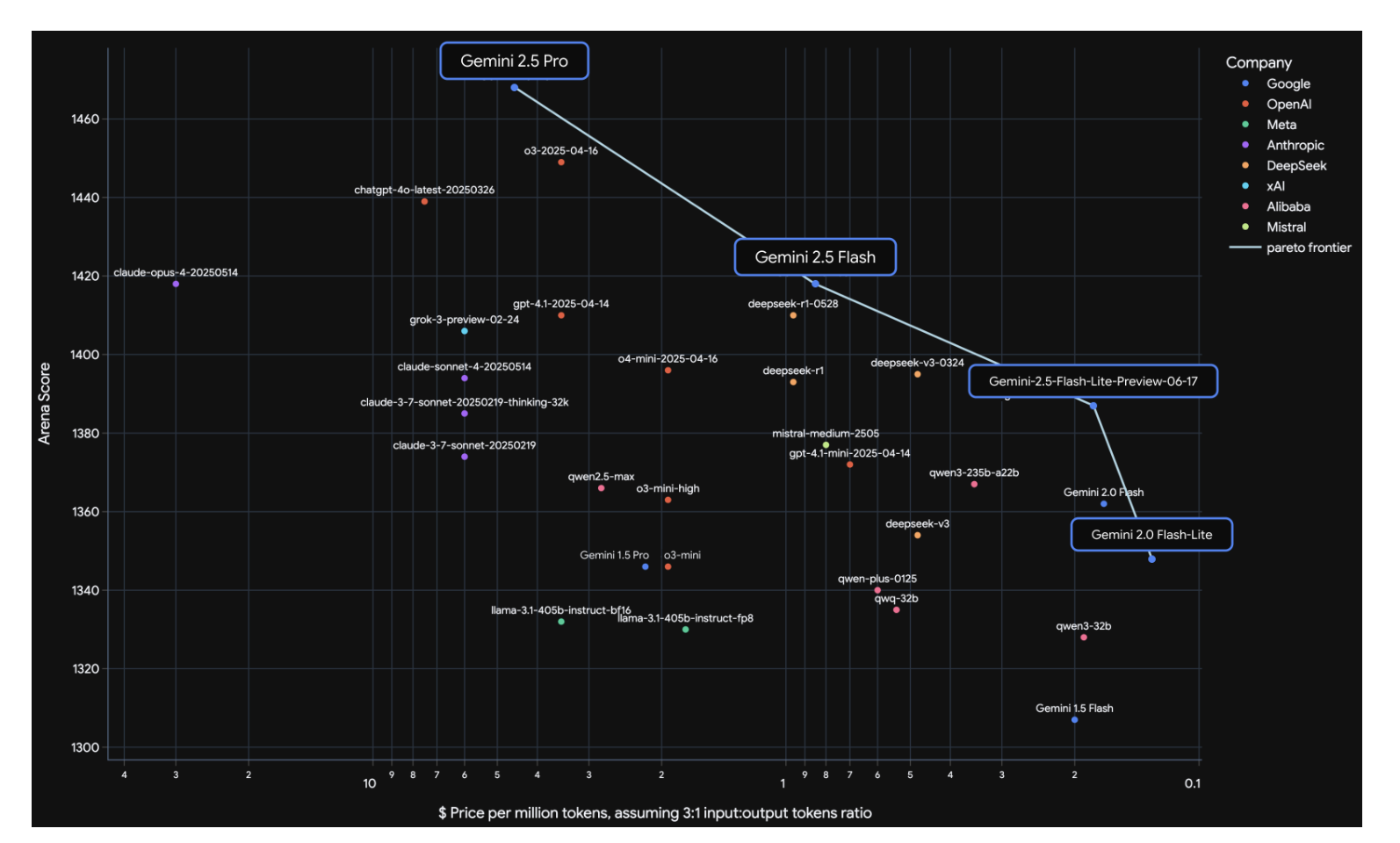 Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic CapabilitiesarXiv preprint arXiv:2507.06261, 2025
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic CapabilitiesarXiv preprint arXiv:2507.06261, 2025 - ACL 2025T-REG: Preference Optimization with Token-Level Reward RegularizationarXiv preprint arXiv:2412.02685, 2024
- ICLR 2025Instructional Segment Embedding: Improving LLM Safety with Instruction HierarchyarXiv preprint arXiv:2410.09102, 2024
- EMNLP 2024WPO: Enhancing RLHF with Weighted Preference OptimizationIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
- ICML 2024Switchable Decision: Dynamic Neural Generation NetworksProceedings of the ICML 2024, 2024
- PreprintAutoML-GPT: Automatic Machine Learning with GPTarXiv preprint arXiv:2305.02499, 2023
- ICLR 2023Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-Oriented Dialogue SystemsarXiv preprint arXiv:2302.10342, 2023
- EMNLP 2022Passage-Mask: A Learnable Regularization Strategy for Retriever-Reader ModelsIn Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022
- NeurIPS 2022A unified framework for alternating offline model training and policy learningAdvances in Neural Information Processing Systems, 2022
- ICML 2022Regularizing a Model-based Policy Stationary Distribution to Stabilize Offline Reinforcement LearningIn International Conference on Machine Learning, 2022
- EMNLP 2021Learning from uneven training data: Unlabeled, single label, and multiple labelsarXiv e-prints, 2021
- ICLR 2021Contextual dropout: An efficient sample-dependent dropout modulearXiv preprint arXiv:2103.04181, 2021
- PreprintFusedream: Training-free text-to-image generation with improved clip+ gan space optimizationarXiv preprint arXiv:2112.01573, 2021
- ACL 2021Knowing more about questions can help: Improving calibration in question answeringarXiv preprint arXiv:2106.01494, 2021
- ICML 2021Bayesian attention belief networksIn International Conference on Machine Learning, 2021
- NeurIPS 2020Bayesian attention modulesAdvances in Neural Information Processing Systems, 2020
Service
Area Chair: ACL 2024-2025, EMNLP 2024-2025, ICML 2024-2025, AAAI 2024-2025
Reviewer: AAAI 2022–2024, ACL 2020–2023, EMNLP 2019–2023, NeurIPS 2020-2024, ICLR 2022-2025, ICML 2020-2025